Introduction¶
This is a learning project to practise XML and SQL data wrangling using actual OpenStreetMap data. Some map data such as street names, postal codes or phone numbers shall be audited automatically and possibly corrected. Furthermore, all corrections might be contributed to the gorgeous OpenStreetMap-Project. After storing the map data to a SQLite database, some SQL requests are demonstrated which cycling enthusiasts might find interesting.
The OpenStreetmap XML data was downloaded using Overpass-API https://overpass-api.de/api/map?bbox=10.6622,51.5293,12.0465,52.2715 for a portion of Saxony-Anhalt.
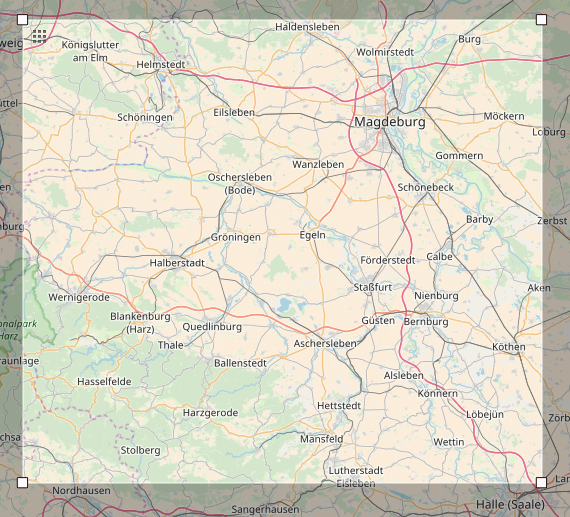
This is the area where I was born. The size of the dataset is 799 MB (838,025,562 bytes).
"""
Your task in this exercise has two steps:
- audit the OSMFILE and change the variable 'mapping' to reflect the changes needed to fix
the unexpected street types to the appropriate ones in the expected list.
You have to add mappings only for the actual problems you find in this OSMFILE,
not a generalized solution, since that may and will depend on the particular area you are auditing.
- write the update_name function, to actually fix the street name.
The function takes a string with street name as an argument and should return the fixed name
We have provided a simple test so that you see what exactly is expected
"""
import xml.etree.cElementTree as ET
from collections import defaultdict
import re
import pprint
import pandas as pd
#OSMFILE = "example4.osm"
#OSMFILE_audited = "example4_audited.osm"
OSMFILE = "magdeburg.osm" # https://overpass-api.de/api/map?bbox=11.5257,52.0597,11.8436,52.2518
OSMFILE = "magdeburg_harz.osm" #https://overpass-api.de/api/map?bbox=10.6622,51.5293,12.0465,52.2715
OSMFILE_audited = "magdeburg_audited.osm"
street_type_re = re.compile(r'\b\S+\.?$', re.IGNORECASE)
has_numbers_re = re.compile(r'[0-9]+')
def is_street_name(elem):
return (elem.attrib['k'] == "addr:street")
def is_postcode(elem):
return (elem.attrib['k'] == "addr:postcode")
def audit(osmfile):
osm_file = open(osmfile, "r", encoding='utf-8')
street_types = defaultdict(set)
postcode_types = defaultdict(set)
'''
Usage of defaultdict(set)
>>> s = [('red', 1), ('blue', 2), ('red', 3), ('blue', 4), ('red', 1), ('blue', 4)]
>>> d = defaultdict(set)
>>> for k, v in s:
... d[k].add(v)
...
>>> d.items()
[('blue', set([2, 4])), ('red', set([1, 3]))]
'''
for event, elem in ET.iterparse(osm_file, events=("start",)):
if elem.tag == "node" or elem.tag == "way":
for tag in elem.iter("tag"):
if is_street_name(tag):
audit_street_type_func(street_types, tag.attrib['v'])
#if tag.attrib['v'] == 'Wiesenstr':
# print(tag.attrib)
# print("id:{0}; lat={1};lon={2}".format(elem.attrib['id'], elem.attrib['lat'], elem.attrib['lon']))
if is_postcode(tag):
audit_postcode_type_func(postcode_types, tag.attrib['v'], elem=elem)
osm_file.close()
return {'street_types': street_types, 'postcode_types': postcode_types}
def update_name(name, mapping):
street_types = defaultdict(set)
#street_types = {}
audit_street_type(street_types, name)
print("update_name")
pprint.pprint(dict(street_types) )
bad_str = list(dict(street_types).keys())[0]
name = name.replace(bad_str, mapping[bad_str])
# YOUR CODE HERE
return name
# Supporting function to get element from osm file
# Takes as input osm file and tuple of nodes and yield nodes of types from tuple.
def get_element(osm_file, tags=('node', 'way', 'relation')):
context = iter(ET.iterparse(osm_file, events=('start', 'end')))
_, root = next(context)
for event, elem in context:
if event == 'end' and elem.tag in tags:
yield elem
root.clear()
# This function replace abbreviations in osm file
# Takes 2 osm file names as input and replace all abbreviations of streets in
# first file. Saves new file under new name (new_file)
# Inspired from: https://github.com/neviadomski/OpenStreetMap-Python-SQL/blob/master/OsmData.py
def improve_streetnames(old_file, new_file):
with open(new_file, 'wb') as output:
output.write('<?xml version="1.0" encoding="UTF-8"?>\n'.encode(encoding='utf-8', errors='strict') )
output.write('<osm>\n '.encode(encoding='utf-8', errors='strict') )
for i, element in enumerate(get_element(old_file)):
for tag in element.iter("tag"):
if is_street_name(tag):
tag.set('v',update_name(tag.attrib['v'], mapping))
output.write(ET.tostring(element, encoding='utf-8'))
output.write('</osm>'.encode(encoding='utf-8', errors='strict'))
Audit street names¶
Auditing german street names can certainly be a matter of science, because many exceptions and regional specialities are possible. Most commonly, street names may end with words (or sub-strings) like "Straße", "Weg", "Chaussee", "Ring", "Platz", "Tor", "Steg", "Stieg", "Garten", "Park", "Brücke". A few less common names where added while auditing the dataset iteratively and are listed in the code below.
expected = ["Street", "Avenue", "Boulevard", "Drive", "Court", "Place", "Square", "Lane", "Road",
"Trail", "Parkway", "Commons"]
expected = ["Straße", "Weg", "Chaussee", "Ring", "Platz", "Tor", "Steg", "Stieg", "Garten", "Park", "Brücke",
"Aue", "Teich", "ldchen", "Breite", "Damm", "Allee", "Hof", "Berg", "Grund", "Weiler", "Weiher", "Gang",
"Gasse", "Feld", "Felde", "Markt", "Werder", "Hafen", "Wuhne", "Bogen", "Blick", "Dorf", "Felsen",
"Winkel", "Wall", "Busch", "Denkmal", "Dom", "Einheit", "Graben", "Bruch", "Kanal", "Weide", "Pfad",
"Leben", "Ehle", "Elbe", "Fahrt", "Fort", "Steig", "Rain", "Ufer", "Wache", "Sprung", "Grube", "Tal",
"Ecken", "Friedens", "Brunnen", "Anger", "Schlag", "Scheid", "Krug", "Höhen", "Hügel", "Keller", "Schule",
"Frieden", "Kuhle", "Börse", "Gesang", "Walde", "Ruh", "Schänke", "See", "Mühle", "Werk", "Revier", "Berge",
"Schleife", "Plan", "Wiese", "Beck", "Fähre", "Wacken", "Gärten", "Gärtnerei", "Bad", "Horn", "Theater",
"Bahn", "Eck", "Haus", "Horst", "Lake", "Wellen", "Pfuhl", "Hufe", "Kamp", "Förder", "Form", "Wiesen",
"Kaserne", "Leuchte", "Kopf", "Pappel", "Deich", "Kopf", "lerei", "Siedlung", "Stadion", "Turm", "Spitze",
"Rondell", "Neuber", "Born", "Thie", "Marsch", "Promenade", "Gelände", "Insel", "Wände", "Schleuse",
"Domäne", "Sülze", "Wacke", "Scholle", "Zitadelle", "Stein", "Heide", "Busche", "Bode", "Burg", "Schloss",
"Schloß", "Wabe", "Wege", "Kreuz", "Reihe", "Treppe", "Höhe", "Kruge", "Dorfe", "Eiche", "Dorn", "Passage",
"Mauer", "Glück", "Jugend", "Lage", "Kirche", "Hain", "Zaun", "Achte", "Klippe", "Loch", "Hang", "Schacht",
"Holz", "Teichen", "Stall", "Halde", "Fabrik", "Wand", "Linden", "Renne", "Halden"]
# UPDATE THIS VARIABLE
mapping = { "St": "Street",
"St.": "Street",
"Rd.": "Road",
"Ave": "Avenue"
}
def audit_street_type(street_types, street_name):
m = street_type_re.search(street_name)
if m:
street_type = m.group()
if street_type not in expected:
street_types[street_type].add(street_name)
def audit_street_type_DE(street_types, street_name):
expected_lower = [el.lower() for el in expected]
m = street_type_re.search(street_name)
if m:
street_type = m.group() # Returns the last element
if not street_type.lower().endswith(tuple(expected_lower)) or has_numbers_re.search(street_name): # not in expected:
street_types[street_type].add(street_name)
#print(street_name)
# Set the audit function for the actual language+area
audit_street_type_func = audit_street_type_DE
test = defaultdict(set)
test_names = ['Teststraße', 'T1estweg', 'Meine Wiese', 'A Str.' , 'Falsche Str.', 'Laaanger Weeg']
for strasse in test_names:
audit_street_type_DE(test, strasse)
print("Test data is:")
print(test_names)
print("Candidates for auditing:")
print(test)
Obviously, the OSM street name data is of very good quality and is not featuring easy mistakes such abreviations. However, there are a few findings that have been corrected in the OSM database. Apparently an automatic correction of the findings is not applicable since every finding was (almost) unique.
A very common error in street names might be that the string ends with a number, which should be the house number. However, in some cases this might be correct as illustrated for "Am Hammelberg Weg 1&2".
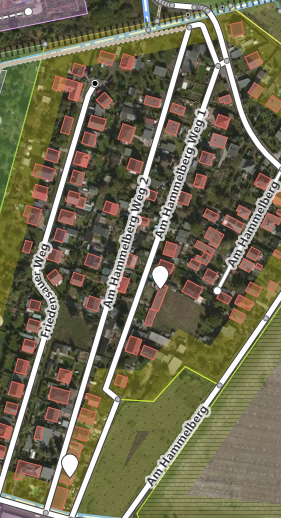
There are no further similar findings in the whole dataset.
Examples of corrections of street names contributed to the OSM-Project¶
However, some errors where identified and corrected in the OSM dataset using the editor iD.
Changeset #59861609: Typo in "Straße":¶
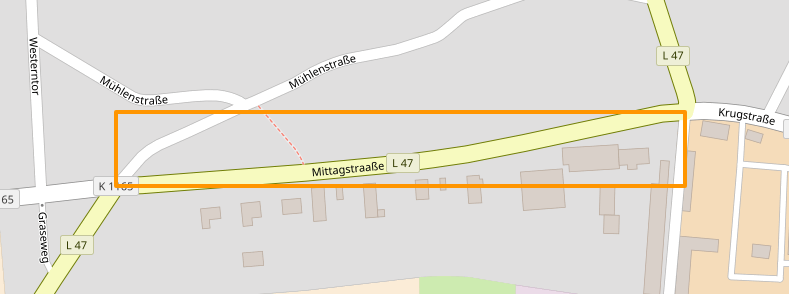
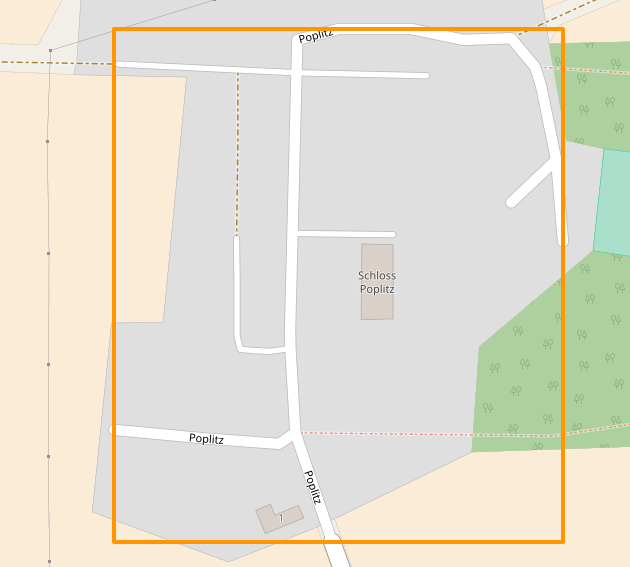
Changeset #59861810: Street name is the name of the place.¶
def mainfunc():
pprint.pprint("Need to improve these names:")
st_types = audit(OSMFILE)
pprint.pprint(dict(st_types))
'''
pprint.pprint("Would update these names")
for st_type, ways in st_types.items(): #.iteritems():
for name in ways:
better_name = update_name(name, mapping)
print(name, "=>", better_name)
#improve_streetnames(OSMFILE, OSMFILE_audited)
'''
if __name__ == '__main__':
print("Not shown in final doc")
#mainfunc()
Audit Postal Codes¶
This is a map of the postal codes of the area. It is used to create the regular expression for auditing of the postal codes.
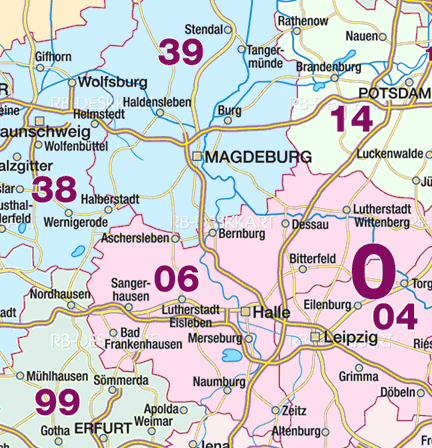
So, the postal code shall eiter start with a "3" or a "0". If it starts with a "3", the following character can be "8" or "9". In case of a "0", the next character must be a "4" or a "6". Three {3} more numerical characters are required to have a valid postal code. A small section of the map has postal codes beginning with "997". The audit_street_type function has been modified for auditing postal codes here. It is tested with the list postalcodes and returns all postal codes that do not match the criteria (in the same way as the street names).
MDPOSTALCODE = re.compile(r'^(3[8,9]{1}[0-9]{3})|(0[4,6]{1}[0-9]{3})|(997[3,5,6]{1}[0-9]{1})')
#(VW (Golf|Polo)|Fiat (Punto|Panda))
def check_postcode(codestr, check_re):
if check_re.match(codestr):
return codestr
else:
return None #""
def audit_postcode_type_DE(postcode_types, postcode_str, elem=None):
postcode_type = postcode_str[0:2]
if not check_postcode(postcode_str, MDPOSTALCODE):
if elem:
auditdetails = {
"addr:postcode":postcode_str,
'id':elem.attrib['id']#,
#'lat':elem.attrib['lat'], 'lon':elem.attrib['lon']
}
postcode_types[postcode_type].add(str(auditdetails))
else:
postcode_types[postcode_type].add(postcode_str)
# Set the audit function for the actual language+area
audit_postcode_type_func = audit_postcode_type_DE
test = defaultdict(set)
postalcodes=['39118','3822','06456','22123','37123','03456','38521','99734']
for postalcode in postalcodes:
audit_postcode_type_DE(test, postalcode)
print(test)
# Works! But TLDR. So not executed in the final document
audit_results = audit(OSMFILE)
audit_results['postcode_types']
Regarding the postal codes, the data quality seems to be very good as well. There is only one finding in the observed area: "96449" is not from this area - it does not even exist. The node can be investigated in the browser using this link: https://www.openstreetmap.org/node/5638689921 (not the same anymore) The node references a hospital (german: e.g. "Klinikum") and the postal code should be "06449" instead.
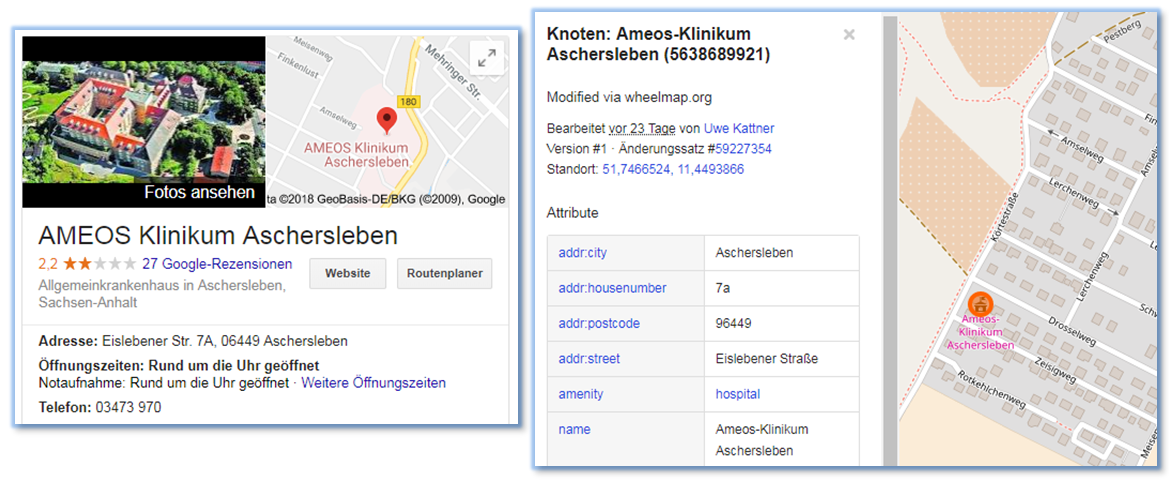
But wait... let's have a closer look at the pictures above. Is this really the same building on the map and the aerial image? Maybe not... The white markers in the image below are pointing to the correct (right) and the wrong (left) position of the hospital. The image is a screenshot is showing the OSM-editor iD in operation used to delete the wrong node. The changeset is #59886196
Obviously the link above is now telling the news that the node was deleted by shuita (me). So, humans might still be useful for auditing more complex things...
Creating tables of nodes, nodes_tags, ways, ways_tags and storing all into a SQLite DB¶
The XML-data shall now be committed into a SQLite database enabling convenient an quick queries on the map data.
In theory, it would be a good opportunity, to perform data cleaning within the transformation process from XML to SQL. However, as explained in the previous chapter, this huge dataset was checked and is of excellent quality. Thus, compiling (simple) automatic data correction functions for street names or postal codes is not very interesting and has obviously no added value to the OSM-Project.
In order to transform the XML to the SQL, the instructions and code snippets from Udacity advised to perform the transformation in two steps:
- From XML to tables in CSV format
- Commit tables in CSV format to SQLite But why doing something in two steps what can be done in one step easier and faster? I think it is time to come up with an update of the old process. As a big advantage, this approach seems to be adequate to prevent character encoding for other languages.
The class UnicodeDictWriter is replaced by Sqlite3TableWriter. Its implementation and usage beautyfies the original function process_map as shown below. The full code is convert_osm2sql.py.
class Sqlite3dbFile(object):
"""Base class just to open an SQLite3-DB file"""
def __init__(self, fname="magdeburg.sqlite3"):
self.connlite3 = sqlite3.connect(fname)
def __enter__(self):
return self
def __exit__(self, exc_type, exc_value, traceback):
self.connlite3.close()
class Sqlite3TableWriter(object):
"""Same thing as UnicodeDictWriter but using SQLite3 db"""
def __init__(self, sqlite3db, table_name, table_columns):
self.db = sqlite3db.connlite3
self.tn = table_name
self.tc = table_columns
self.cache_pdf = pd.DataFrame(columns=table_columns)
self.cache_list = [] # Faster than pd.DataFrame.append!
def writerow(self, row):
self.cache_list.append(row) # Pre-allocation would be faster, but this works...
def writerows(self, rows):
for row in rows: # TODO: store rows in dataframe
self.writerow(row)
def commit_db(self): # Some caching might be reasonable...
self.cache_pdf = pd.DataFrame(self.cache_list, columns=self.tc)
self.cache_pdf.to_sql(self.tn, self.db, if_exists="append")
# ================================================== #
# Main Function #
# ================================================== #
def process_map(file_in, validate):
"""Iteratively process each XML element and write to csv(s)"""
with Sqlite3dbFile("magdeburg_harz.sqlite3") as dbfile:
nodes_writer = Sqlite3TableWriter(dbfile, "nodes", NODE_FIELDS)
node_tags_writer = Sqlite3TableWriter(dbfile, "nodes_tags", NODE_TAGS_FIELDS)
ways_writer = Sqlite3TableWriter(dbfile, "ways", WAY_FIELDS)
way_nodes_writer = Sqlite3TableWriter(dbfile, "ways_nodes", WAY_NODES_FIELDS)
way_tags_writer = Sqlite3TableWriter(dbfile, "ways_tags", WAY_TAGS_FIELDS)
validator = cerberus.Validator()
print("Processing the Map...")
counter = 0
counter_disp = 0
for element in get_element(file_in, tags=('node', 'way')):
counter = counter + 1
if counter > 100000: # Alive-ticker...
counter = 0
counter_disp = counter_disp + 1
print("Parsing elements (in 100k):{0}".format(counter_disp))
el = shape_element(element)
if el:
if validate is True:
validate_element(el, validator)
if element.tag == 'node':
nodes_writer.writerow(el['node'])
node_tags_writer.writerows(el['node_tags'])
elif element.tag == 'way':
ways_writer.writerow(el['way'])
way_nodes_writer.writerows(el['way_nodes'])
way_tags_writer.writerows(el['way_tags'])
print("Done!")
print("Committing to SQLite-DB...")
nodes_writer.commit_db()
print("Committing to SQLite-DB...")
node_tags_writer.commit_db()
print("Committing to SQLite-DB...")
ways_writer.commit_db()
print("Committing to SQLite-DB...")
way_nodes_writer.commit_db()
print("Committing to SQLite-DB...")
way_tags_writer.commit_db()
This creates the SQLite database and produces the following output:
import convert_osm2sql
convert_osm2sql.run_process_map()
Database Overview¶
To provide an illustrative overview of the data and table architecture of OSM data stored in an SQL database, some sample data is shown in the following:
import pandas as pd
import sqlite3
from IPython.display import display, HTML, Image
connlite3 = sqlite3.connect("magdeburg_harz.sqlite3")
c = connlite3.cursor()
Nodes¶
querystr = "SELECT DISTINCT nodes.* FROM nodes INNER JOIN nodes_tags ON nodes_tags.id = nodes.id ORDER BY id LIMIT 3"
c.execute(querystr)
rows = c.fetchall()
columns = []
for column_pos in range(len(c.description)):
columns.append(c.description[column_pos][0])
pdf = pd.DataFrame(rows, columns=columns)
HTML(pdf.to_html())
Nodes_tags¶
#querystr = "SELECT * FROM nodes_tags ORDER BY id LIMIT 3"
querystr = "SELECT nodes_tags.* FROM nodes INNER JOIN nodes_tags ON nodes_tags.id = nodes.id ORDER BY id LIMIT 10"
HTML(pd.read_sql_query(querystr, connlite3).to_html())
Ways_nodes¶
#querystr = "SELECT * FROM ways LIMIT 3"
querystr = "SELECT ways_nodes.* FROM ways_nodes INNER JOIN nodes ON ways_nodes.node_id = nodes.id ORDER BY ways_nodes.node_id LIMIT 10"
HTML(pd.read_sql_query(querystr, connlite3).to_html())
Ways¶
querystr = "SELECT ways.* FROM ways INNER JOIN ways_nodes ON ways.id = ways_nodes.node_id ORDER BY ways_nodes.node_id LIMIT 10"
HTML(pd.read_sql_query(querystr, connlite3).to_html())
Ways_tags¶
querystr = "SELECT ways_tags.* FROM ways_tags INNER JOIN ways ON ways_tags.id = ways.id ORDER BY ways.id LIMIT 10"
HTML(pd.read_sql_query(querystr, connlite3).to_html())
Some numbers¶
These are some basic statistics on the map data of the area:
querystr = "SELECT count() FROM ways"
num_ways = pd.read_sql_query(querystr, connlite3).iloc[0,0]
querystr = "SELECT count() FROM ways_tags"
num_ways_tags = pd.read_sql_query(querystr, connlite3).iloc[0,0]
print("Number of ways(*1000) / Average number of tags per way: {0} / {1}".format( num_ways/1000.0, num_ways_tags/num_ways ))
querystr = "SELECT count() FROM nodes"
num_nodes = pd.read_sql_query(querystr, connlite3).iloc[0,0]
querystr = "SELECT count() FROM nodes_tags"
num_nodes_tags = pd.read_sql_query(querystr, connlite3).iloc[0,0]
print("Number of nodes(*1000) / Average number of tags per node: {0} / {1}".format( num_nodes/1000.0, num_nodes_tags/num_nodes ))
querystr = "SELECT count() FROM (\
SELECT DISTINCT usr.user FROM (\
SELECT DISTINCT user FROM nodes UNION ALL SELECT DISTINCT user FROM ways\
) \
usr)"
print("Number of (distinct) contributors: {0}".format( pd.read_sql_query(querystr, connlite3).iloc[0,0] ))
querystr = "SELECT count(*) FROM (\
SELECT unc.user, \
unc.nodes_count, \
uwc.ways_count, \
(unc.nodes_count + uwc.ways_count) AS total_count \
FROM (\
SELECT user, count(*) AS nodes_count \
FROM nodes \
GROUP BY user\
) unc \
INNER JOIN (\
SELECT user, count(*) AS ways_count \
FROM ways \
GROUP BY user\
) uwc \
ON unc.user = uwc.user \
WHERE unc.nodes_count > 30 AND uwc.ways_count > 10 \
ORDER BY total_count DESC \
)\
"
num_active_distinct_users = pd.read_sql_query(querystr, connlite3).iloc[0,0]
print("Number of active contributors: {0} (more than 30 nodes and 10 ways)".format( pd.read_sql_query(querystr, connlite3).iloc[0,0] ))
Top contributers by number¶
not considering quality...
querystr = "SELECT unc.user, \
unc.nodes_count, \
uwc.ways_count, \
(unc.nodes_count + uwc.ways_count) AS total_count \
FROM (\
SELECT user, count(*) AS nodes_count \
FROM nodes \
GROUP BY user\
) unc \
INNER JOIN (\
SELECT user, count(*) AS ways_count \
FROM ways \
GROUP BY user\
) uwc \
ON unc.user = uwc.user \
ORDER BY total_count DESC \
LIMIT 20"
HTML( pd.read_sql_query(querystr, connlite3).to_html() )
Map usage - POI's for cyclists¶
As a passionate cyclist I am always interested in bicycle related places in my area. Let's start with a query of nodes that have been somehow tagged with "bicycle", excluding cycleways, traffic signs and parkings.
# Which POI's (grouped by key) exist?
# First query all data from id's that have something to do with bicycle --> mit self join
querystr = "SELECT nt.id, nt.type, nt.key, nt.value FROM nodes_tags nt \
INNER JOIN (\
SELECT DISTINCT id \
FROM nodes_tags \
WHERE (\
key LIKE '%bicycle%' AND key NOT LIKE '%left%' AND key NOT LIKE '%right%' \
AND NOT key='bicycle'\
) OR (\
key IN ('shop', 'amenity') AND value LIKE '%bicycle%' AND NOT value='bicycle_parking'\
)\
) id_sel ON nt.id = id_sel.id"
HTML( pd.read_sql_query(querystr, connlite3).head(20).to_html() )
This form of representation is not very well suited for humans. A pivoted representation would be better human readable and preferred. It is straigthforward to do the job with a Pandas-DataFrame. Of course, this is also possible with pure SQL:
querystr = "SELECT id\
, MAX(CASE WHEN key='name' THEN value END) name\
, MAX(CASE WHEN key='street' THEN value END) strasze\
, MAX(CASE WHEN key='housenumber' THEN value END) nr\
, MAX(CASE WHEN key='city' THEN value END) city\
FROM (\
SELECT nt.id, nt.type, nt.key, nt.value FROM nodes_tags nt \
INNER JOIN (\
SELECT DISTINCT id \
FROM nodes_tags \
WHERE (\
key LIKE '%bicycle%' AND key NOT LIKE '%left%' AND key NOT LIKE '%right%' \
AND NOT key='bicycle'\
) OR (\
key IN ('shop', 'amenity') AND value LIKE '%bicycle%' AND NOT value='bicycle_parking'\
)\
) id_sel ON nt.id = id_sel.id\
)\
GROUP BY id"
HTML( pd.read_sql_query(querystr, connlite3).head(10).to_html() )
What a bad surprise! Many tags, particularly the adresses, are missing! In order to find the place anyway, we can join and information from the nodes table. Works for most people in times of GPS & Co. However, there is certainly room for improvement on the map data...
querystr = "SELECT n_tags.*, n.lat, n.lon FROM (\
SELECT id\
, MAX(CASE WHEN key='name' THEN value END) name\
, MAX(CASE WHEN key='street' THEN value END) strasze\
, MAX(CASE WHEN key='housenumber' THEN value END) nr\
, MAX(CASE WHEN key='city' THEN value END) city\
FROM (\
SELECT nt.id, nt.type, nt.key, nt.value FROM nodes_tags nt \
INNER JOIN (\
SELECT DISTINCT id \
FROM nodes_tags \
WHERE (\
key LIKE '%bicycle%' AND key NOT LIKE '%left%' AND key NOT LIKE '%right%' \
AND NOT key='bicycle'\
) OR (\
key IN ('shop', 'amenity') AND value LIKE '%bicycle%' AND NOT value='bicycle_parking'\
)\
) id_sel ON nt.id = id_sel.id\
)\
GROUP BY id\
) n_tags\
INNER JOIN (\
SELECT id, lat, lon FROM nodes\
) n\
ON n_tags.id = n.id \
ORDER by n_tags.city, n_tags.name, n.lon"
HTML( pd.read_sql_query(querystr, connlite3).to_html() )
68 places... but 7 are not even tagged (yet) with a name.
Conclusions and more ideas¶
Semi-automatic map data auditing and corrections have been performed in this project. However, some more advanced checks would be desireable - since these are just simple plausibility checks for common human mistakes. They do not ensure, that the data is correct at all. This would require the usage of more reference datasets or more advanced heuristics (e.g. the usage of lat/lon to verify the postal codes).
Some corrections were contributed to the OpenStreetMap project. These are the corresponding changesets:
Änderungssätze von shuita
- Straßennahmen korrigiert (Schreibfehler) #59862237
- Straßennahmen korrigiert (Schreibfehler) #59862205
- Straßennahmen korrigiert (Schreibfehler) #59861978
- Straßennahme war Ortsnahme #59861926
- Straßennahme war Ortsnahme #59861810
- Straßennahmen korrigiert (Schreibfehler) #59861609The audited data has been transformed to SQLite tables. The transformation process was (in my point of view) simplified and improved by directly writing the dictionaries to SQL tables rather than writing them to CSV tables in an intermediate step. Furthermore, this approach prevents character encoding problems with foreign languages.
Some queries were demonstrated, e.g. statistics on map data contributors and points of interest for cycling enthusiasts. Although the overall quality of the OSM map data is very good, many incompletely tagged nodes were found for this example*. So there is likely in gerneral certain room for improvement regarding the completeness of tags.
import sys
print(sys.version)
connlite3.close()
*I am probably going to fix this when I am at home the next time with my bicycle B~)